
Synopsis
- There is a new style of AI (artificial intelligence) that has, in recent years, taken the world by storm. Called Deep Learning, this approach has made possible self-driving cars, enhanced voice and image recognition, and audible translation from one language to another; to name just a few breakthroughs. Most of what we observe being done in such areas would have been only the stuff of science fiction as recently as 15 or 20 years ago.
- Much of my career was spent creating computer models to analyze the world of finance and investments. For 30 years, beginning in the mid-1970s, I was involved in cutting-edge research that explored ways to control risk, identify arbitrage opportunities, and find value-added investments for the money managers, pension funds, governments, and foundations who were my clients.
- For most of that period, AI was only a curiosity; a field in which the ideas were bigger than the capacity of computers to carry them out. If you saw the movie The Imitation Game, you may remember the scene in which the computer took more than 24 hours to solve the Nazi code, which changed daily. A few years later, a famous mathematician came to UMass in Amherst for a guest lecture, and announced that he was now able to forecast tomorrow’s weather. The catch was, he admitted, that the calculations were so complex it would take him a month to do it. But eventually, these problems became tractable, and computers “learned” to play chess and do other amusing things in real time.
- In the latter phase of my computer modeling days, I played with primitive forms of AI, such as neural networks, and feedback models. I found these approaches to be useful additions to the work I was doing, although I realized I could not do all that I would like because of capacity constraints (on my time and in computer power).
- I’m delighted to find that the things I could only imagine 15 years ago are now being implemented on a large scale. I take no credit for promulgating these ideas; they were the next logical step in the technology of the time. I only hope that these recent rapid advances pressage solutions to some of our most vexing problems. I’m optimistic because I don’t like to think of the cost of failure.
The Old Days
I worked on Wall Street in the 1980s for Morgan Stanley, one of the most technologically advanced companies of the day. Indeed, many of my early projects involved creating automated trading systems to execute sophisticated strategies that simply could not be done efficiently by a human trader.
We had at our disposal IBM’s most powerful and sophisticated mainframe computers, and we coded in APL, a language well-suited to the large data matrices that we needed to handle. Some of the models I created would bring these computers to their knees, so it was clear we were working at the frontiers of this kind of analysis.
When a technical problem arose, I had a number I would call for assistance. The person at the other end would always answer, “VR, how can I help you?” and I would explain my situation. One day, after I’d been working there a while, I asked a co-worker, “What does ‘VR’ stand for?” Oh, I was told, that stands for “voice recognition.” It seems that there had been an ambitious effort to save the traders from writing a ticket for each trade. Instead, they would call a phone number and recite the terms of the trade and it would be recorded directly on the computer system. The tests went well, and all the traders were trained, and they threw away their paper pads. But in real life, it was a disaster! Quickly, a fall-back plan was implemented. Instead of the computer answering the phone call, an actual person would take the call and write up the ticket, then enter it into the computer system. “Voice recognition,” to be sure — the old-fashioned way.
Machines Who Learn
There was an article in the June 2016 issue of Scientific American by this title, linked to (but behind a pay wall) in this write-up. The editorial choice of the pronoun is telling. Machines have begun to think like people. Instead of being pre-programmed to anticipate every possible situation (an impossibility), they are now made to learn from experience, as humans and other living beings do.
The article points out that the advances in AI have been made possible by improvements on two fronts; hardware and software. The hardware of 30 years ago was unable to cope with the demands of even (by today’s standards) simple systems. Among other innovations, there has been (at least) a 10-fold increase in computing speed
thanks to the graphics-processing units initially designed for video games…
On the software side, the early primitive neural networks have moved away from a static, linear model to more sophisticated feedback algorithms.
Reading about this brought back fond memories for me, of my days playing with early versions of these approaches. By the time these models had come into experimental use, I had gone off on my own, and had neither the resources nor the time to pursue them in the ways I could envision them being used. I was too busy earning a living, which involved a lot of expert witness work and real-world forecasting. I wish there had been more time to do pure research, although I did play around enough with the ideas, in what little time I could spare, to derive some insights that helped with the services I offered. That analysis included models I used to forecast foreign exchange rates, among other things.
The following graphic from the SciAm article brought me chuckles of recognition. Recognition of the natural, human variety, that is, not the kind mentioned here:
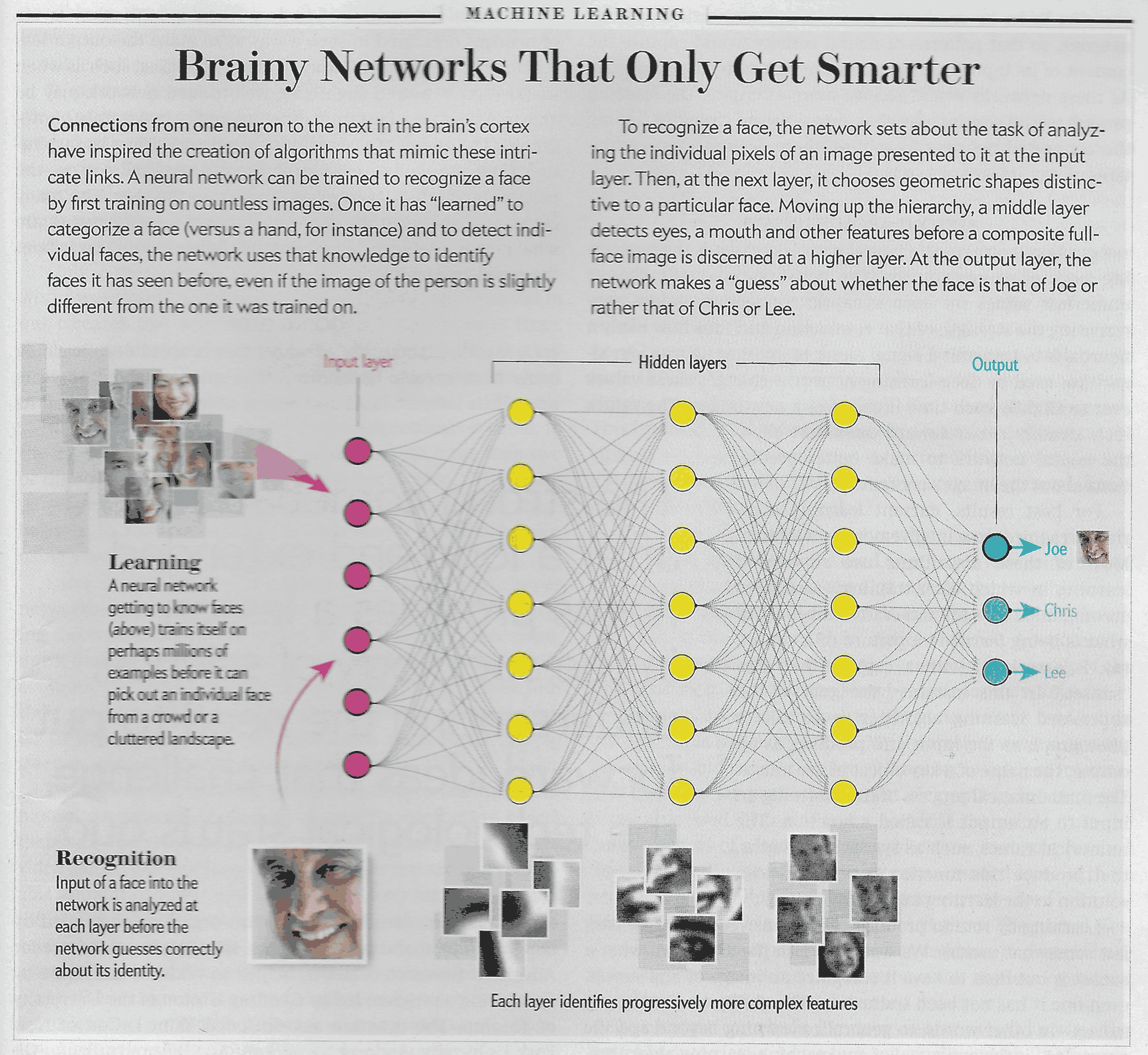
The basic structure shown here is identical in concept to the primitive neural networks that I created 15 or 20 years ago. Choices are made as to how many input nodes there are to be. This would correspond to information thought to be relevant to the problem at hand. In the case of forecasting currency exchange rates, for example, these inputs might include interest rates, inflation rates, the price of oil, and other exchange rates, among many other variables.
An arbitrary number of “hidden layers” is chosen (guided by experience, to be sure), and historical data are fed into the algorithm, which produces a forecast that can then be compared with the actual historical outcome. The network is “trained” on a bunch of such data until its internal coefficients are deemed to have reached an “optimal” level for forecasting.
I’m being vague here because I don’t want to get bogged down in technical detail. Suffice it to say that I did not find this approach to be very useful. The obvious problems are that there may be relevant variables that had not been included in the data set, or that the historical period studied may not be representative of the world going forward. And the structure in those early days did not allow for the model, once in place, to learn from its experience.
These same criticisms, by the way, could have been leveled against the more conventional econometric models of the time. Those models did not have “hidden layers” but they were linear and static. They worked fine until they didn’t, when the world changed, or some catastrophic event occurred.
I felt a need for a more dynamic approach, and at the time I was learning about complexity theory.
[All of this talk about my work is good material for another post (so stay tuned); for now, just some hints!]
I became familiar with a 1976 paper by Robert May (now Lord May), a naturalist who studied animal population fluctuations. He analyzed the effects of (unrealistically) high growth rate assumptions in the logistic difference equation. This equation had been around for a long time (first published in 1845), and was used to predict the ups and downs of population density. May demonstrated that this equation, which had long been thought to be quite orderly, could in fact produce chaotic results. The thing that intrigued me about this equation was not so much its transition from the orderly regime into the chaotic (which was indeed fascinating), but that it had what I would come to call a “learning coefficient.”
This equation has a feedback component, because the prediction for the next period depends on an estimate of the population’s natural growth rate (assumed to be the same over time), and a measurement of how close the population size is to its maximum (the largest population its environment could sustain). Of course these values cannot be known with precision, but using historical observations as approximations will produce graphs (or maps) that look very much like what happens in nature.
What I took away from my study of this equation was the idea that there could be a built-in “error correction” that could operate dynamically. In the case of animal populations, the corrections were made by a natural response to the availability of resources. When a population is small relative to food supply, growth is rapid. As the size of the population nears its maximum, starvation will reduce the population back to the point that it can start growing again. In real life, things are more complex than this, because of predator/prey interactions — but I digress!
Referring back to the currency-forecasting model I mentioned; my complaint had been that its operation was too dependent on the data set that was arbitrarily chosen as being “typical” of what the future might bring. And it was difficult to know when the world might have changed enough to warrant re-estimating the model. But what if the model could learn from experience? I figured out a way to do this, and I’ll spare you the details, but my tests showed that my new approach was superior to the one I had been using (at least it was when tested on historical data).
So I went “live” with the new model, and incorporated it into the research and advice I was selling. It continued to work well. Mind you, in the world of economics and finance (a bit like weather, I guess), there is no such thing as an “accurate” forecast. The standard, rather, it whether a forecasting algorithm is better than others that are available. Being a little bit better than the competition is all that can be hoped for (and is rewarded) in the fast-paced world of financial markets.
I had dreams of going the next step, which would have involved letting the computer learn how to adjust other features of the model. Adding another layer, in other words, in which the algorithm would “teach” the components that were already learning, by observing their performance and adjusting how they made their adjustments.
I never got to do that, however, because, as the ancient saying goes, life is what happens while you are making other plans. For various reasons, I decided to exit the business, and never got to play with my next level of ideas.
Imagine my delight, then, when I saw the diagram above, and from the description in the article, realized that my vision was now a reality, and is what is driving this new wave of AI.
I’m not claiming any credit for promulgating these ideas, because I did not. They were an obvious outgrowth of the work that was going on 10 to 15 years ago, as I was winding down my involvement. At the time, as the SciAm article discusses, computing power was inadequate to solve many real-world problems. I was already working at the fringes of this line of computing, and it wasn’t easy. But it sure was fun. And it’s fun for me now to see where things have gone.
I have every reason to believe that in another 10 or 15 years, we will be witnessing new applications that are only a glimmer today. Perhaps we will even figure out how to ameliorate the vexing problems that threaten us today, such as overpopulation, deforestation, species loss, and climate change. I’d like to think we can do that, because I don’t want to contemplate the alternative.